Was drin steckt, kommt raus: Datenqualität und Expertenwissen als Grundlage unserer KI-Assistenten
Beim Streifzug durchs Internet trifft man sie rechts unten. Meistens. Chatbots sind inzwischen allgegenwärtig. Die meisten von uns haben wahrscheinlich schon beide Sorten kennengelernt: den Bot, der in kürzester Zeit für erhöhten Blutdruck oder Fragezeichen über dem Kopf sorgt, und den, der tatsächlich weiterhilft.
Die Frage ist: Was unterscheidet Chatbots, die verärgern, von solchen, die ‚verstehen‘, die auf den Punkt sind und beispielsweise stundenlange Recherchen ersparen?
Wir möchten einen Einblick geben, welche Überlegungen uns bei der Einführung unserer eigenen KI-Assistenten geleitet haben, was uns dabei wichtig war und was wir dabei gelernt haben.
Ein Chatbot für Massenabwicklung – oder als Abkürzung zur Expertise?
 Es hat eine Weile gedauert, bis wir verstanden haben, dass ein KI-Assistent für unsere Zwecke grundlegend andere Anforderungen erfüllen muss als bei der hundertfachen Abwicklung von Reklamationen oder der Beantwortung von FAQs aus Handbüchern oder Gebrauchsanweisungen. In manchen Geschäftsmodellen ist genau das sinnvoll: Der Chatbot als Filter vor dem eigentlichen Kundenkontakt. Günstig, skalierbar, effizient.
Es hat eine Weile gedauert, bis wir verstanden haben, dass ein KI-Assistent für unsere Zwecke grundlegend andere Anforderungen erfüllen muss als bei der hundertfachen Abwicklung von Reklamationen oder der Beantwortung von FAQs aus Handbüchern oder Gebrauchsanweisungen. In manchen Geschäftsmodellen ist genau das sinnvoll: Der Chatbot als Filter vor dem eigentlichen Kundenkontakt. Günstig, skalierbar, effizient.
Bei HessenChemie arbeiten wir anders. Unsere KI-Assistenten sind eine jederzeit verfügbare Ergänzung zur persönlichen Beratung – kein Ersatz. Sie dürfen Standardfragen zügig beantworten, müssen aber auch Ihre Grenzen, beispielsweise zur Einzelfallberatung, erkennen und entsprechend abgeben bzw. weiterverweisen. Sie sind also in vielen Fällen eine Abkürzung, um schneller zu den kritischen Punkten zu gelangen, für die echte Expertise gefragt ist. Und sie erschließen und bereiten die Tiefe unseres Wissens auf nutzerfreundliche Weise auf, das sich im Mitgliederbereich findet, im Blog, in Tarifverträgen, Praxishilfen, Fachmeldungen und Schulungsunterlagen.
Gute KI braucht eine gute Datenbasis – und Menschen, die ihr Fach verstehen
 Wenn ich in Gesprächen mit Mitgliedsunternehmen von unserem KI-Assistenten erzähle, kommt früher oder später die Frage: „Und wie habt ihr dem beigebracht, was er wissen muss?“ Die ehrliche Antwort: wie bei jedem Praktikanten war das keine Sache von ein paar Tagen – und schon gar nicht die Arbeit einer einzelnen Person.
Wenn ich in Gesprächen mit Mitgliedsunternehmen von unserem KI-Assistenten erzähle, kommt früher oder später die Frage: „Und wie habt ihr dem beigebracht, was er wissen muss?“ Die ehrliche Antwort: wie bei jedem Praktikanten war das keine Sache von ein paar Tagen – und schon gar nicht die Arbeit einer einzelnen Person.
Was uns im Anlernprozess wirklich geholfen hat, war etwas, das wir über Jahre hinweg aufgebaut hatten, ohne dabei an KI zu denken: eine Datenbasis mit aktuellen arbeitsrechtlichen Mustern, verständlichen Praxishilfen, sauber strukturierten Dokumenten, Checklisten und Erläuterungen. Ohne diese Vorarbeit wäre das Training deutlich mühsamer gewesen. Garbage in, garbage out – das gilt hier genauso wie überall sonst in der Datenarbeit. Und genau dieses Fundament kommt uns nun zugute.
Keine Abkürzung für Antwortqualität
Den eigentlichen Sprung nach vorn ermöglichen jedoch nicht die Daten allein, sondern deren Ergänzung durch unsere Expertinnen und Experten für Arbeits- und Tarifrecht, Kommunikation und betriebliche Personalpolitik. Im Trainingsprozess haben wir unsere Arbeit reflektiert und uns dabei auf folgende Fragen konzentriert:
Die Antworten der KI müssen all diese Grundüberlegungen widerspiegeln. Deshalb haben wir sie unserer Agentur vermittelt, die sie wiederum dem Sprachmodell übersetzt hat. Das klingt aufwendig? Es ist etwas Mühe und Arbeit, aber es gibt keine Abkürzung.
Ohne diese Vor- und Eigeninvestition gibt es kein wertvolles Training und keine schnell ansteigende Lernkurve. Wer erwartet, ein Sprachmodell einfach „einzuschalten” und sofort praxistaugliche Ergebnisse für einen spezifischen Arbeits- und Anwendungskontext zu erhalten, wird enttäuscht sein. Das gilt für uns genauso wie für Betriebe, die KI-Werkzeuge in ihre HR-Prozesse integrieren möchten. Aber es gilt noch mehr zu beachten.

Unser KI-Assistent: Datenschutz first – und trotzdem flexibel
Wer einen KI-Assistenten einführt steht schnell auch vor der Frage: Welches Sprachmodell nutzen wir und wo läuft das Ganze eigentlich?
Keine Abhängigkeit von einem bestimmten LLM
Uns war von Anfang an eine Sache wichtig: Wir wollten uns nicht an ein bestimmtes Sprachmodell (Large Language Model, LLM) und KI-Unternehmen binden. Die KI-Landschaft entwickelt sich rasend schnell. Was heute State of the Art ist, kann morgen schon überholt sein. Zudem gleichen sich die Sprachmodelle bei gebräuchlichen Nutzungsszenarien stark an. Deshalb haben wir von Beginn an auf eine flexible Architektur gesetzt.
Aktuell läuft im Hintergrund ein Modell des französischen Anbieters Mistral, ein Open-Source-Modell, das sich in unserem Setup sehr gut bewährt hat. Wenn wir morgen ein Modell für geeigneter halten, können wir wechseln, ohne das System von Grund auf neu aufzubauen.
Welche Vorteile bieten Open-Source-Sprachmodelle?
Der Einsatz quelloffener Sprachmodelle im eigenen Rechenzentrum gibt Organisationen die volle Kontrolle über drei entscheidende Dimensionen:
- Datenschutz: Sämtliche Konversationsdaten verbleiben in der eigenen Infrastruktur. Es entstehen keine Abhängigkeiten von Lösch- und Aufbewahrungsrichtlinien externer Anbieter – ein wesentlicher Vorteil bei der Verarbeitung personenbezogener oder vertraulicher Inhalte.
- Kostenstruktur: Der Eigenbetrieb löst die nutzungsabhängige Token-Abrechnung kommerzieller API-Dienste ab und ermöglicht planbare, pauschale Preismodelle – unabhängig vom tatsächlichen Gesprächsvolumen.
- Versionskontrolle: Modellwechsel und Updates erfolgen gezielt und zum selbstgewählten Zeitpunkt. Das verhindert unangekündigte Verhaltensänderungen, wie sie bei API-basierten Diensten durch serverseitige Aktualisierungen auftreten können.
Datenschutz ist kein Anhängsel – sondern Grundbedingung
Außerdem ist sichergestellt, dass die eingegebenen Daten in Deutschland bleiben. Unsere Hosting-Infrastruktur ist ISO-zertifiziert und wird vollständig auf deutschen Servern betrieben. Das mag nach einer Selbstverständlichkeit klingen, ist in der Praxis aber leider nicht immer der Fall.
Aus Gründen der Datensparsamkeit enthält unser Chat auch keine Funktion zum Hochladen von Dateien. Dies könnte der Eingabe vieler persönlicher Daten Vorschub leisten und entspricht nicht der von uns angestrebten Nutzung.
Noch ein Punkt, der in dieser Hinsicht wichtig ist: Die Modelle werden nicht mit Daten trainiert. Was Nutzerinnen und Nutzer eingeben, bleibt genau das – eine Eingabe im Rahmen des jeweiligen Kontextfensters, keine Trainingsgrundlage für irgendein zukünftiges Modell. Auch das ist bei vielen kommerziellen KI-Lösungen anders oder kann zumindest nicht sichergestellt werden.
Unser KI-Assistent lernt weiterhin – mit Ihrer Hilfe
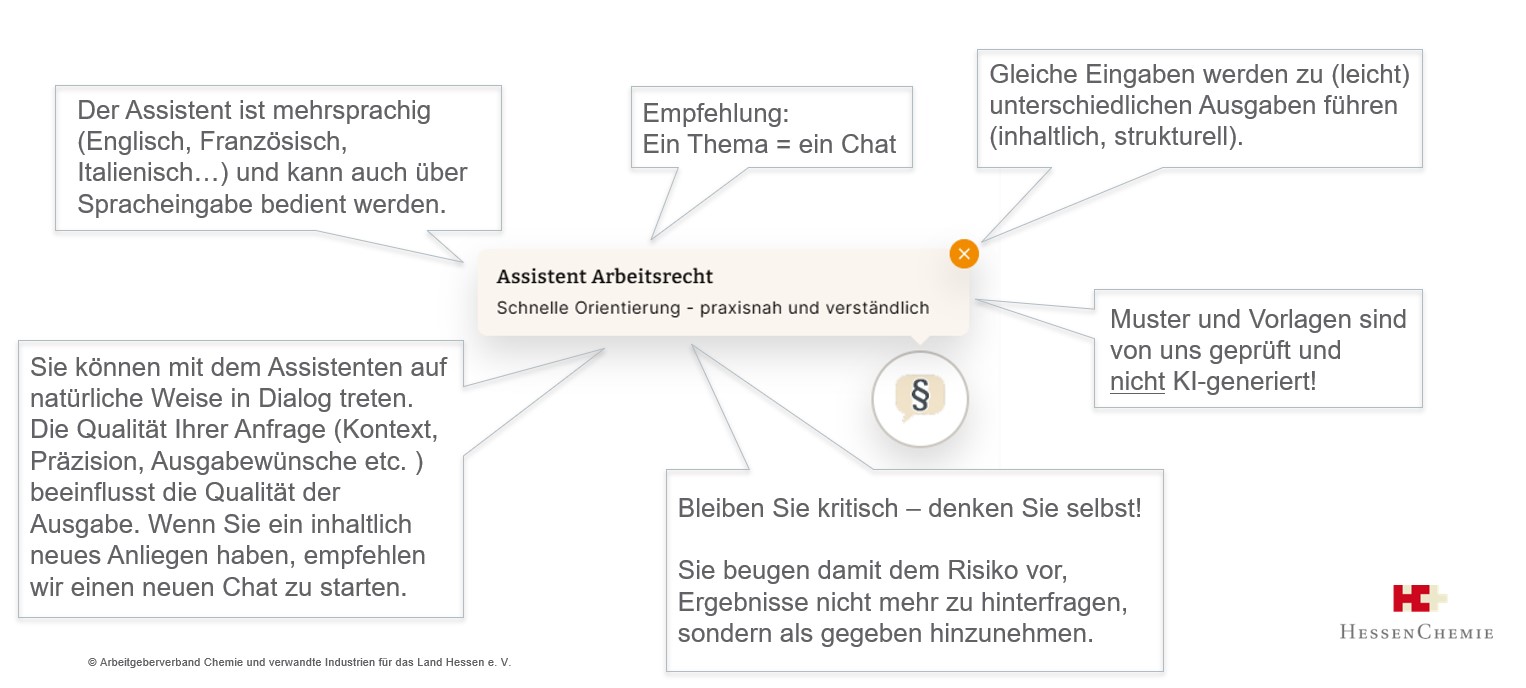
Kennen Sie das? Sie stellen eine ganz konkrete Frage, doch der Chatbot antwortet mit etwas, das zwar irgendwie zum Thema passt, Ihre Situation aber komplett verfehlt. Das ist kein Einzelfall, sondern ein Strukturproblem. Unbefriedigende KI-Systeme agieren zu starr entlang fester Muster. Sie „verstehen” die Welt der Fragenden nicht wirklich und scheitern oft schon, wenn die Frage ein bisschen von der Norm abweicht oder ein neuer Kontext ins Spiel kommt.
Hierbei hilft Domänenwissen – nicht als nettes Extra, sondern als Grundbedingung. Genau deshalb beziehen wir bei der Fortentwicklung unseres KI-Assistenten auch weiterhin Rückmeldungen von Fachleuten mit ein, die die Welt der hessischen Chemie- und Pharmaunternehmen kennen. Sie decken Bereiche wie Tarifrecht, Demografieberatung und konkrete Alltagsfragen aus den Personalabteilungen unserer Mitgliedsunternehmen ab. Die Feedback- und Kommentarfunktion jedes einzelnen Chatverlaufs steht uns darüber hinaus in Kürze in einem Dashboard zur Verfügung, so dass wir auch Fragen und Anmerkungen wahrnehmen, die uns auf klassischem Wege nicht erreicht haben und die wir ebenfalls in unseren Verbesserungsprozess einspeisen können.
Technik ist das eine – Nutzererlebnis das andere
Guter Fachinhalt allein reicht jedoch nicht aus. Wer ein digitales Tool nicht gerne benutzt, benutzt es in der Regel gar nicht. Es sind auch Aspekte der Handhabung, die darüber entscheiden, ob ein KI-Helfer tatsächlich zum Alltagshelfer wird.
Vielleicht öffnet man einen neuen Chat und stellt fest, dass das System noch den alten Kontext mitschleppt. Oder die Antwort ist prima, aber wie exportiert man sie jetzt? Oder man arbeitet in einem internationalen Team und fragt sich: Geht das eigentlich auch auf Englisch oder Französisch?
Ja, das sind Kleinigkeiten. Solche praktischen Reibungspunkte können jedoch darüber entscheiden, ob ein Tool wirklich Tag für Tag mit Freude benutzt wird – oder nach zwei Wochen in der Versenkung verschwindet. Es dürfte klar sein, was wir uns wünschen :) Lassen Sie uns daher gemeinsam daran arbeiten, dieses Produkt zu einem selbstverständlichen Teil Ihres Arbeitsalltags zu machen.

Clemens Volkwein

Clemens Volkwein ist Demografieberater für die hessischen Unternehmen aus Chemie, Pharma und Kunststoffverarbeitung. Hysterie in der Demografie-Debatte hält er für überflüssig, gute Ideen hingegen nicht, wie sich die Alterung und Schrumpfung unserer (berufstätigen) Bevölkerung positiv gestalten lassen.



{kind=link}
{kind=link}
{kind=link}